
Anastasiya Novikava
Copywriter
Anastasiya believes cybersecurity should be easy to understand. She is particularly interested in studying nation-state cyber-attacks. Outside of work, she enjoys history, 1930s screwball comedies, and Eurodance music.
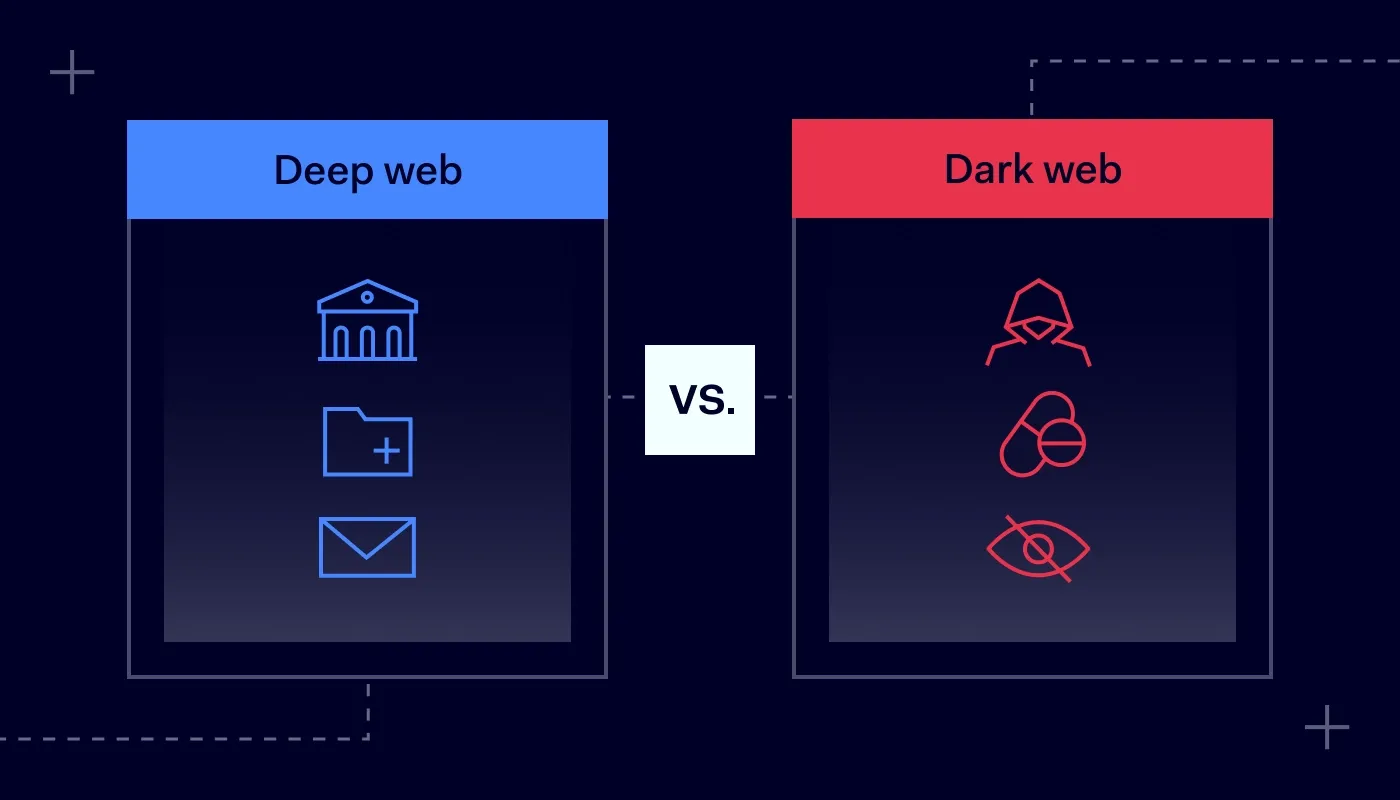
Summary: The deep web is most of the internet that search engines can’t index, like your email. The dark web is a hidden subset that requires Tor and prioritizes anonymity.
The terms “deep web” and “dark web” are often used interchangeably, but they’re not the same thing at all. You probably use one of them every day without realizing it.
In short, the deep web contains all the web pages that standard search engines can’t find, like, for example, your private email or online banking. The dark web is a small, purpose-built part of the deep web that uses special software to maximize anonymity. Knowing the deep web vs. dark web distinction is crucial for staying safe online.
The deep web is, simply put, the majority of the internet. It’s not a single place, but a collective term for all the web pages that are not indexed by commercial search engines like Google or Bing. Because these pages are unindexed, you can’t stumble upon them with a simple search query.
Why is so much of the web “hidden” like this? For perfectly normal and necessary reasons. Access to this deep web content is usually restricted by authentication or other barriers, and many pages are deliberately kept out of search engines via logins, paywalls, robots.txt, or “noindex” tags.
You access the deep web every day using your normal browser. It’s the backbone of a private, functional internet.
The dark web is a specific part of the deep web that is intentionally hidden and designed for anonymity. It operates on “darknets,” which are overlay networks that run on top of the regular internet. The best-known darknet is Tor (“The Onion Router”).
Tor works by wrapping your connection in multiple layers of encryption and routing it through a network of volunteer-run relays. This makes it difficult to trace activity back to you or identify a server’s physical location.
Tor delivers stronger anonymity than typical browsing, but it cautions that “perfect anonymity” is impossible. Dark web browsing, therefore, increases privacy, but it is not foolproof. Websites there use the special .onion suffix and are meant to be accessed with the Tor Browser.
Close the tabs on browser threats. Open one for security
Your first line of defense starts at the Business Browser

While the dark web is a subset of the deep web, they serve different functions. The confusion between the deep and dark web often comes from this technical overlap, but they differ in scale, accessibility, and purpose.
Here's a quick cheat sheet to tell them apart:
Feature | Deep web | Dark web |
|---|---|---|
Definition | Any part of the web not indexed by search engines. | An intentionally hidden subset of the deep web built for anonymity. |
Size | Vast (most of the internet), exact size unknown and not directly measurable. | Much smaller than the surface web and hard to quantify. |
Accessibility | Accessed with a standard browser (Chrome, Safari, etc.). | Requires special software like the Tor Browser. |
Content | Private/controlled data: emails, banking, medical records, databases. | Ranges from legal (activism, whistleblowing) to illegal content and markets. |
Anonymity | Not inherently anonymous; tied to user accounts and permissions. | Designed to maximize user anonymity, though not absolute. |
URL structure | Standard domains (.com, .net, .gov). | Uses special .onion domains. |
Let's explore these differences in more detail.
When you compare the deep web vs dark web by size, the difference is stark. The deep web holds the bulk of online data—dynamic web pages, databases, and private services—whereas the dark web represents a much smaller slice that is intentionally hidden.
Exact counts aren’t reliable for either, but reputable sources agree the dark web is only a small fraction of the deep web. In discussions about the deep and dark web, size is often misunderstood because neither space can be fully crawled or measured.
What inflates the deep web’s footprint is how much content is generated on the fly. Many business systems, academic databases, and SaaS apps render results only after a user query or login, creating web pages that search engines cannot access. Even public-facing sites can opt out of indexing through robots.txt and meta “noindex” directives, keeping pages out of search by design. By contrast, most dark web content lives on ephemeral .onion services that may change addresses, disappear, or get mirrored—further limiting any census.
Neither the deep web nor the dark web has a stable “site list.” Deep web applications sit behind SSO, MFA, and paywalls; their URLs and query parameters shift constantly as data changes.
On the dark web, operators frequently rotate .onion addresses to mitigate DDoS, takedowns, or deanonymization attempts. Many .onion sites are clones or temporary mirrors, and “link hubs” are often outdated within days. This churn makes the deep and dark web difficult to quantify with confidence, so the safest framing is relative: the deep web is vast; the dark web is small.
Your daily interactions with the deep web happen through a standard browser. You reach email, cloud storage, or HR portals via logins; access control verifies identity, and activity is usually attributable to a specific account. Discovery typically occurs via intranet dashboards, direct links, or bookmarks because resources are intentionally gated or de-indexed.
Accessing the dark web is different. You need the Tor Browser (or another compatible client) to connect to the Tor network and visit .onion addresses; Chrome or Safari won’t open them directly. Discovery also differs: there is no comprehensive “Google for Tor.” A few niche search engines (like Ahmia) and community-curated directories exist, but coverage is partial and link quality varies. As a result, newcomers often rely on trusted recommendations and verified directories rather than broad search, which helps avoid stale links and malicious lookalikes.
The deep web’s purpose is to protect sensitive data while enabling everyday work. Think banking portals, medical records systems, ERPs, CRMs, and internal wikis where permissions, auditing, and compliance matter.
The dark web’s purpose is anonymity. That anonymity supports legitimate needs (for example, whistleblowing or circumventing censorship) but also attracts misuse. It is frequently leveraged for illegal activities such as trading stolen credentials, malware, and contraband on dark web marketplaces and forums.
International operations routinely target sites and vendors that facilitate illegal activities, and takedowns are common. Even passive browsing can expose users to scams, malware, or solicitations for illegal activities, so strong operational security is essential.
For organizations, the deep and dark web present different risk profiles: protect deep web apps and data with strict access controls and monitoring, and treat external exposure (malicious domains, phishing sites, and leaked credentials) as an intelligence and filtering challenge. Security teams that understand how the deep and dark web are built and accessed can prioritize controls where they matter most without relying on myths or inflated claims.
Strong security practices are essential. Dark web threats include malware, scams, and exposure to illegal content and actors.
Here are some critical steps to protect yourself.
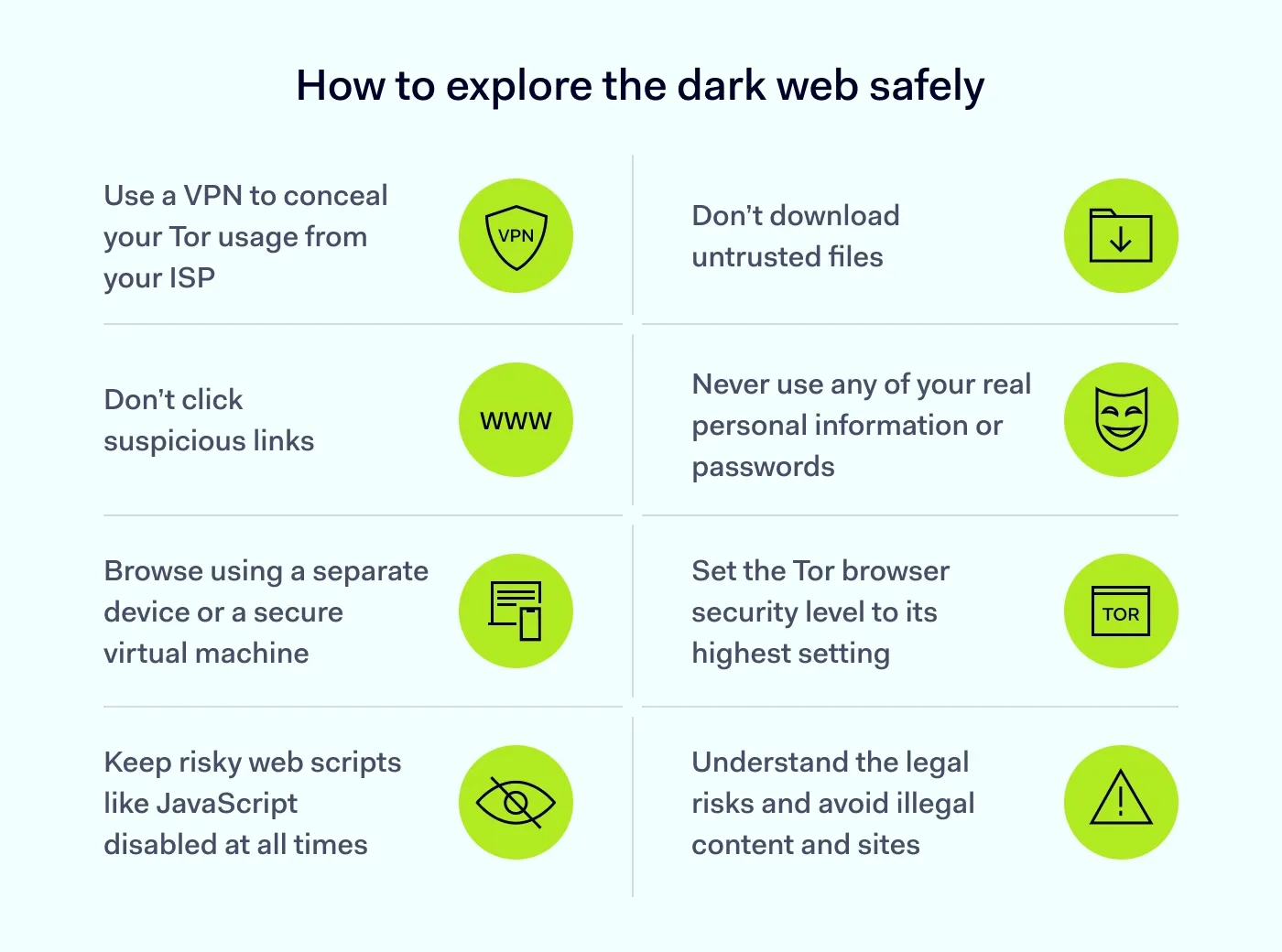
Tor prevents observers (like your ISP) from seeing which sites you visit, but your provider can usually see that you are using Tor. A reputable VPN can mask that fact by hiding your traffic from the ISP, though it shifts trust to the VPN and is not required for Tor to work. Bridges (secret Tor entry points that help you connect when regular ones are blocked) are another option where Tor is censored.
This rule applies to the whole internet but is especially vital on the dark web. Do not download any files from sources you don't trust completely. Files are often bundled with malware designed to steal your data or compromise your device.
Be equally suspicious of links. Phishing is a common tactic used to mimic legitimate services and trick you into revealing personal information.
Keep the Tor Browser updated and avoid plugins. Never use any personally identifiable information when dark web browsing. This means no real name, no standard email address, no reused passwords, and certainly no personal photos.
If you must create an account on a .onion site, use a completely new and anonymous identity with a secure, disposable email address. For maximum security, experts recommend using a dedicated device or a virtual machine that is completely separate from your personal files.
The Tor Browser comes with security settings that you should use. Its highest security level disables many web scripts (like JavaScript) by default. Keep it that way.
Malicious scripts can be exploited to reveal your real IP address or other data, breaking the anonymity that Tor provides. It may also sound cliché, but cover your webcam with a piece of tape. It's a simple, physical barrier that works if your device is ever compromised.
Simply visiting the dark web out of curiosity isn't illegal in most countries. However, engaging with its illicit side is. Viewing, downloading, or purchasing illegal content or services can have severe legal consequences. Stay far away from dark web marketplaces and any forums centered around illegal activities. Anonymity is not a get-out-of-jail-free card; law enforcement agencies have dedicated significant resources to tracking criminals on the dark web.



For businesses, the stakes are higher. Credentials exposed on criminal forums and dark web marketplaces often originate from third-party data breaches, while malicious links target employees on the open web. NordLayer helps reduce exposure in areas you directly control while providing visibility into external threats.
This approach is crucial from a risk-management viewpoint. It protects your assets with strong access controls and blunts external threat exposure.
Anastasiya Novikava
Copywriter
Anastasiya believes cybersecurity should be easy to understand. She is particularly interested in studying nation-state cyber-attacks. Outside of work, she enjoys history, 1930s screwball comedies, and Eurodance music.
Subscribe to our blog updates for in-depth perspectives on cybersecurity.


