What is AI data security?

In January 2025, Wiz Research went looking at DeepSeek's public-facing infrastructure and found a ClickHouse database open on the internet. It had no password, offered full control, and inside, it had more than a million log lines: chat histories, API secret keys, and backend details. The model itself was working as designed, but the data around it was not. DeepSeek closed the exposure, but the lesson was that in AI, the most damaging breach is sometimes not the model, but the data the model touches, generates, and writes to a log.
Not all security teams are aware of this type of AI risk. Firewalls and identity providers protect the systems around the model, but they do very little about the data flowing through it.
Key takeaways
- AI data security protects the data that AI systems train on, retrieve from, generate, and log.
- AI data security covers confidentiality, integrity, availability, provenance, and privacy pillars.
- The biggest AI data security risks are data poisoning, prompt injection, sensitive information disclosure, retrieval-augmented generation (RAG) and embedding leaks, model inversion, data drift, shadow AI, and agent tool misuse.
- Real incidents, disclosed vulnerabilities, and research demonstrations (Samsung, OpenAI, Hugging Face, DeepSeek, Slack AI, Microsoft 365 Copilot's EchoLeak, Meta AI, LAION-5B, ShadowRay) show the failure modes are already in production.
- Authoritative guidance comes from NIST AI RMF, the NSA/CISA/FBI/NCSC AI data security paper, OWASP Top 10 for LLM applications, MITRE ATLAS, ISO/IEC 42001, and the EU AI Act.
- AI data security best practices start with governance: an inventory of AI systems and data, classification, least privilege, encryption, provenance tracking, prompt and output controls, RAG hardening, red teaming, and continuous monitoring.
What is AI data security
AI data security is the set of policies, controls, and practices that protect the confidentiality, integrity, availability, provenance, and privacy of data across the AI lifecycle, so AI systems cannot leak sensitive information, learn from compromised data, produce unsafe outputs, or act on untrusted inputs.
In a traditional application, data is an asset you protect from theft and tampering. But in an AI application, data is also an instruction. Models learn behavior from training data, take orders from prompt data, pull context from retrieval data, and produce new data as output.
That is why AI data security covers a wider surface than most teams expect. It includes source data, training and fine-tuning sets, evaluation benchmarks, prompts and chat history, retrieval-augmented generation (RAG) corpora and embeddings, generated outputs, feedback signals, logs and telemetry, and the metadata that proves where any of it came from. The guidance issued by NSA, CISA, FBI, and international cyber agencies states that data security controls must apply to every dataset used to design, develop, deploy, operate, and maintain AI and ML systems.
NIST frames the same idea through trust. Its AI Risk Management Framework says AI systems should be valid, reliable, safe, secure, resilient, accountable, transparent, explainable, interpretable, privacy-enhanced, and fair, with harmful bias managed. Data sits underneath every one of those properties. A model is only as private as the data it was trained on; only as fair as the labels it learned from; only as reliable as the corpus it retrieves from at inference time.
How data flows through an AI system
Data enters AI systems continuously, from many sources, with very different trust levels.
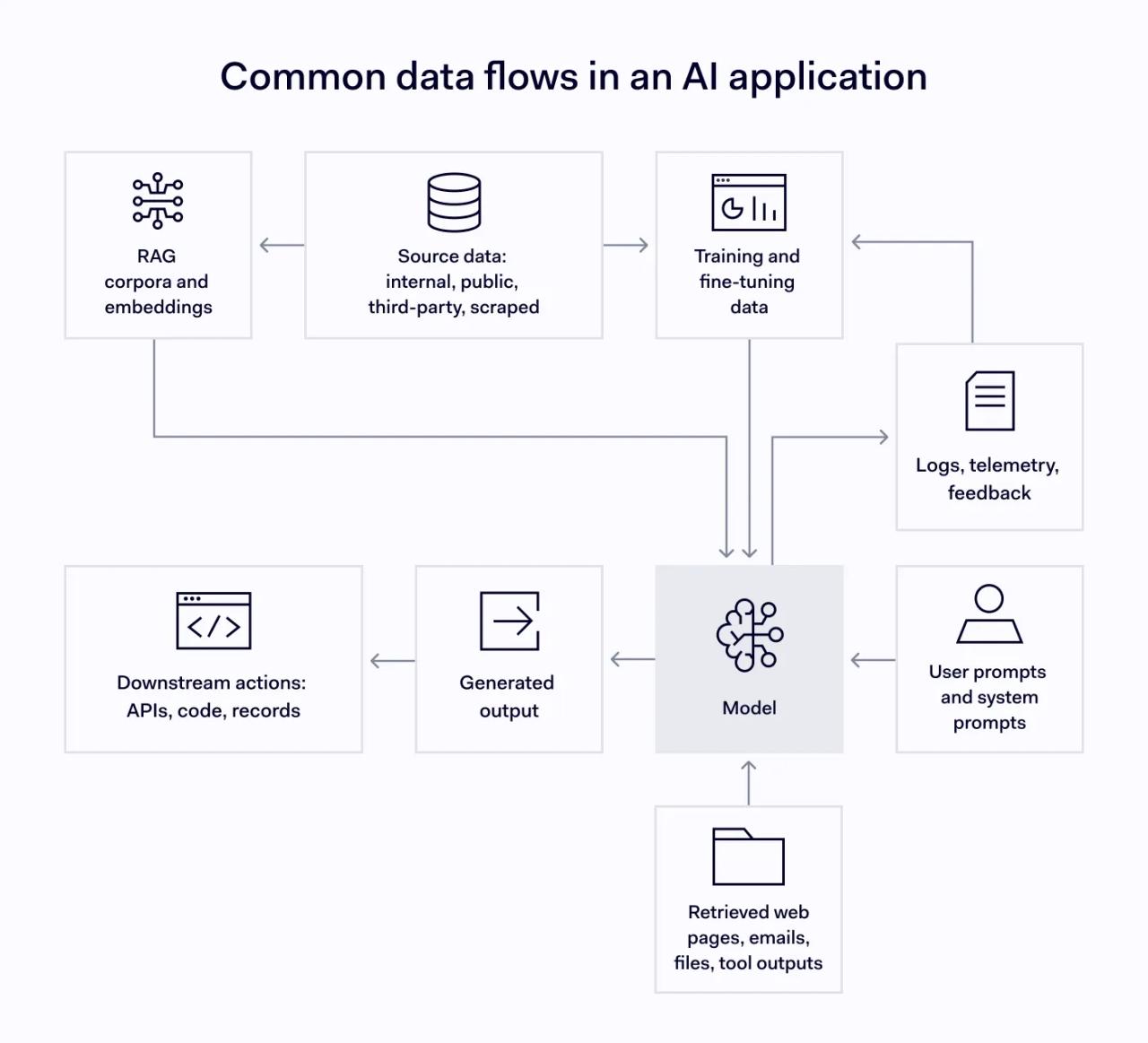
Each arrow is also an attack path, and each node is a potential leak. That is the territory AI data security is trying to cover.
AI data security vs. AI security
AI security is the broad discipline: securing models, applications, APIs, infrastructure, identities, agents, supply chains, and incident response. AI data security is the data-centered subset, focused on a smaller set of questions:
- What data is used to train, tune, test, prompt, retrieve, and monitor the system?
- Who can access that data, and under what authority?
- Can the data be trusted, and can we prove it?
- Can the model expose the data?
- Can an attacker alter the data to alter the system?
- Can the output itself become a new source of risk?
To have an AI data security program, teams must answer all those questions.
Why AI and data security cannot be treated separately
The temptation, especially in larger organizations, is to bolt AI onto an existing data security program and call it done. The reasoning is reasonable on its face: data security teams already classify data, manage access, encrypt at rest, and run data loss prevention (DLP) tools. Surely AI is just another consumer.
It is not, for four reasons.
1. Data shapes model behavior
Traditional applications execute logic written by engineers. Machine learning (ML) models derive logic from data, a point the NSA AI data guidance makes explicitly. Manipulated data can manipulate that logic, often invisibly. A poisoned classifier still passes its unit tests; it just fails on the inputs the attacker cares about.
2. The boundary between data and instructions has collapsed
For generative AI, anything the model reads can become an instruction. A prompt, yes, but also a retrieved document, a webpage, an email, a PDF, an image with hidden text, the output of another tool.
OWASP and Microsoft both treat prompt injection as a top-tier LLM risk because external content can quietly redirect the model to disclose data, take unauthorized actions, or bypass controls.
The 2025 EchoLeak vulnerability in Microsoft 365 Copilot (CVE-2025-32711) showed the mechanism in production: an email could trigger zero-click data exfiltration from a user's Copilot context, with no click or attachment required. Microsoft fixed it and reported no evidence of malicious exploitation, which is the right outcome and also the right warning.
3. Outputs are sensitive too
Generated text often summarizes restricted documents, contains copies of training data, or creates new business records. Logs of prompts and responses can include credentials, customer records, source code, and legal correspondence.
For instance, OpenAI's 2023 Redis bug was a flaw in an open-source client that caused some ChatGPT users to see titles from other active users' chat histories. During a nine-hour window a subset of ChatGPT Plus users had names, email addresses, payment addresses, card expiration dates, and the last four digits of card numbers exposed.
4. The data supply chain is now the AI supply chain
AI systems pull from public datasets, scraped web data, vendor models, partner APIs, data brokers, and open repositories.
In 2023, Stanford Internet Observatory researchers identified entries linking to suspected child sexual abuse material inside LAION-5B, a dataset widely used in generative ML training pipelines. It was pulled and re-released as Re-LAION-5B.
NSA names data supply chain risk as one of the three major AI data risk areas (alongside poisoning and drift) precisely because most organizations cannot say with confidence where their training and retrieval data originated.
Common AI data security concerns
The list below maps to OWASP's Top 10 for LLM Applications, NIST's adversarial ML taxonomy, and the NSA/CISA AI data guidance. It is not exhaustive.
1. Data poisoning
Attackers tamper with training, fine-tuning, or embedding data to degrade performance, plant backdoors, induce bias, or trigger unsafe behavior on specific inputs.
Public datasets, scraped web content, and crowd-sourced feedback are the most common entry points. The LAION-5B episode is a reminder that contamination does not always need a hacker, only a dataset nobody fully audited.
2. Prompt injection
Malicious instructions can be placed directly in user prompts (direct injection) or hidden inside documents, emails, web pages, or images that the model later processes (indirect injection). The result ranges from leaked system prompts to exfiltrated customer data to unauthorized tool calls.
OWASP ranks it LLM01 for a reason. PromptArmor's 2024 demonstration against Slack AI showed indirect prompt injection being used to exfiltrate data from private channels the attacker was not a member of. Slack patched the issue, but the pattern (RAG over internal messages with untrusted content treated as instructions) is now general.
3. Sensitive information disclosure
Models and AI services can surface personally identifiable information (PII), financial data, health data, credentials, proprietary code, customer records, or confidential business information. The DeepSeek ClickHouse exposure leaked chat history, secret keys, backend details, and over a million log lines. Through a database left open on the internet.
4. Model inversion and membership inference
NSA describes model inversion as an attack capable of exposing confidential or proprietary information through patient observation of output patterns. By probing a model's outputs in the right way, a hacker can infer attributes of its training data or confirm whether a specific record was included. Privacy-enhancing techniques such as differential privacy exist precisely to prevent this.
5. RAG and embedding weaknesses
Retrieval pipelines can surface overshared documents, return poisoned context, or expose information through embeddings themselves (which encode chunks of source material in a form that is far from opaque). OWASP added vector and embedding weaknesses as a separate category in its 2025 LLM Top 10. The quiet failure mode here is permission inheritance: the model retrieves what its service account can see, not what the end user is allowed to see. The Slack AI case belongs to this category, and EchoLeak generalized it across email and the wider Microsoft 365 graph.
Compliance and ethical considerations
Compliance and ethics overlap heavily in AI because both ask the same question from different angles: can you justify, to a regulator or to a customer, what your AI system did with their data and why?
A few anchors worth knowing:
- NIST AI RMF and Generative AI Profile. Voluntary in the U.S., but increasingly the de facto baseline for AI risk programs. The Generative AI Profile is particularly useful because it enumerates risks specific to generative systems and maps them to lifecycle stages.
- NSA/CISA/FBI/NCSC AI data security guidance. The most prescriptive public document on data-centric controls: provenance tracking, cryptographic hashes, digital signatures, encryption, classification, secure deletion, and continuous risk assessment.
- ISO/IEC 42001 and ISO/IEC 23894. ISO/IEC 42001 defines an AI management system (like ISO 27001, but for AI). ISO/IEC 23894 provides risk management guidance for organizations that develop, deploy, or use AI systems.
- EU AI Act. Risk-based rules for AI providers and deployers, with specific obligations for general-purpose AI models, including transparency, data governance, and cybersecurity. Penalties are not symbolic.
The ethical layer is harder to checklist but no less consequential. A model trained on scraped data of dubious provenance may be technically compliant in one jurisdiction and indefensible in another (the LAION-5B episode again). Outputs that are statistically accurate can still be discriminatory in effect. Logging every prompt for “quality assurance” can quietly turn an AI assistant into the most invasive surveillance tool the company has ever deployed.
The 2025 Meta AI bug, in which users could access other users' private prompts and generated responses before Meta fixed the issue and paid out a bounty, is a reminder that prompt and response data deserves the same access controls as any other private user record. NIST's trustworthiness characteristics (fairness, transparency, accountability, privacy enhancement) exist as a reminder that legal and right are not synonyms. That's why organizations should document data sources, consent basis, retention, and intended use before the model goes near production. Auditors will ask later; users may ask sooner.
Best practices for AI data security
The following practices are drawn from NSA/CISA/NCSC, NIST, OWASP, Microsoft, Google, MITRE ATLAS, and the lived experience of teams that have already had to clean up after their first incident. They are ordered roughly by how early they pay off.
1. Build an AI and data inventory before anything else
Maintain a registry of AI systems, model providers, datasets, RAG stores, vector databases, prompts, outputs, logs, and the humans accountable for each.
Microsoft pushes the idea of an AI bill of materials (AI BOM) for the same reason a software BOM matters: when something breaks, you need to know what depends on it. Mandiant has noted that most organizations lack basic AI app registries or AI-specific scanners, which is also why most organizations cannot answer questions during an incident.
2. Classify and minimize the data AI uses
Sort data into public, internal, confidential, regulated, and mission-critical buckets before it enters AI pipelines. Then send the model the minimum it needs. The cheapest leak to prevent is the one where the model never had the data in the first place; Samsung learned that the expensive way.
3. Track provenance and protect integrity
Use trusted sources, dataset lineage, version control, hashes, checksums, digital signatures, and tamper-evident logs across training data, fine-tuning sets, evaluation benchmarks, RAG corpora, and feedback. NSA's guidance is explicit about cryptographic verification of data revisions. Provenance is also what lets you respond to “where did this output come from?” without guessing, and what lets you pull a poisoned or unlawful corpus off the shelf the way LAION had to.
4. Apply least privilege at every layer
AI systems should not get blanket access to enterprise data. Use RBAC and ABAC, just-in-time access, service identities, tenant isolation, and crucially, permission checks at retrieval time so the model only sees what the requesting user is entitled to see. Microsoft recommends managed identities over API keys, private endpoints, network isolation, and approved model registries for Azure AI workloads. The same principles apply on any cloud. The Meta AI bug was, at its core, a missing object-level authorization check on prompts and responses.
5. Encrypt data at rest, in transit, and where possible in use
For higher-risk pipelines, evaluate confidential computing, secure enclaves, federated learning, differential privacy, and secure multiparty computation. Most organizations will not need all of them, but nearly all will need more than they currently have.
6. Treat prompts, outputs, and logs as sensitive data
Prompt logs routinely contain credentials, personal data, customer records, source code, and internal strategy. Outputs can summarize restricted material into convenient new artifacts. Teams should apply DLP, sensitivity labels, redaction, retention limits, and audit trails to all three. OWASP's sensitive information disclosure category is largely a story of forgotten log buckets.
7. Defend against direct and indirect prompt injection
Treat every external input (user prompts, retrieved documents, tool outputs, web content) as untrusted. Separate system instructions from user content. Use input and output classifiers, allowlists for tool calls, markdown sanitization, suspicious URL redaction, and explicit user confirmation for high-impact actions.
Google describes this as a layered defense across the prompt lifecycle, which is the right framing: there is no single filter that solves prompt injection, only stacks that make it expensive. Slack AI and EchoLeak both demonstrate why this layering matters in AI assistants.
8. Harden RAG and vector databases
Apply access controls to source documents before they are indexed. Mirror end-user permissions at retrieval time. Treat embeddings as sensitive, because they are; they encode the source. Monitor retrieval results for sensitive content, stale data, and signs of poisoning. OWASP's vector and embedding weaknesses category exists because too many RAG deployments skipped this step.
9. Secure the AI platform
AI-specific platforms and infrastructure are now attack surfaces in their own right. In 2024, Hugging Face disclosed unauthorized access related to Spaces secrets, revoked affected tokens, recommended fine-grained tokens, and reported the incident to authorities.
The ShadowRay campaign, tracked since late 2023, has exploited a Ray AI framework vulnerability to reach AI workloads, models, datasets, cloud tokens, and source code across education, biopharma, cryptocurrency, and other sectors.
Manage AI tokens and API keys, harden the orchestration layer, and assume your AI platform is in scope for both pentests and patch cycles.
10. Red team continuously
Pre-launch testing is necessary and insufficient. Run ongoing exercises covering data poisoning, direct and indirect prompt injection, data exfiltration, model inversion, insecure output handling, RAG permission bypass, and agent tool misuse.
MITRE ATLAS catalogues adversary tactics against AI systems and is a reasonable starting playbook. Microsoft and Mandiant both publish AI red teaming methodologies; the specifics matter less than the cadence.
11. Monitor drift, anomalies, and leakage in production
AI data security does not end at deployment. Watch production inputs, retrieved content, prompts, outputs, logs, data quality, and model behavior. Alert on unusual access patterns, sensitive data appearing where it should not, sudden distribution shifts, and changes in output quality. Finally, maintain incident response plans that include model rollback, data rotation, and credential revocation.
12. Govern shadow AI before it governs you
Discover unsanctioned AI tools in use across the organization, score them by risk, publish a sanctioned alternative for the use cases people actually have, and use DLP to block the worst paste-into-public-chatbot patterns. Microsoft's guidance treats this as a first-class workstream because, in practice, it usually is, and Samsung's restriction of employee genAI use in 2023 is the canonical case study.
13. Plan for decommissioning
Models, datasets, vector stores, and prompt logs all eventually need to be retired. Secure deletion, key destruction, and records of what was disposed of (and when) are part of the lifecycle. NIST's Generative AI Profile flags decommissioning as a distinct lifecycle stage with its own risks; most programs forget it until legal asks.
A short word on AI big data security
The phrase “AI big data security” is used loosely. In reality, the difficulty at scale is not storage or throughput (both of which are solved problems), but rather provenance and control.
When a training corpus runs to hundreds of terabytes drawn from thousands of sources, then proving
- where each piece came from,
- whether its use was authorized,
- whether it has been altered,
- who can access it,
- which downstream models depend on it — becomes a serious engineering problem.
In AI, the data supply chain is part of the AI supply chain.
Conclusion
AI data security is not a new discipline so much as an old one operating under new physics. The frameworks converge on the same shortlist: know your data, restrict access, prove provenance, encrypt aggressively, test adversarially, and monitor what production is actually doing.
None of it is exotic – most of it is the work organizations were already supposed to be doing for the data they had before any of this started talking back. The teams that get ahead of it will look, from the outside, slightly boring. That is the goal.